International Benchmarking Usability Studies
| Outcome | Three product teams aligned on international UX gaps, with features shipped across Experiences and Hotels |
| My role | Lead Researcher |
| Team | International, Experiences, Hotels, and Core UX, Tripadvisor |
| Methods | Unmoderated usability testing, SUPR-Q benchmarking, competitive analysis |
| Participants | 300 Passionate Travellers across France, Italy, and Spain |
| Timeline | Jul to Aug 2023 |
The situation
Tripadvisor had identified Southern Europe as a growth priority. France, Italy, and Spain represented large travel markets where the platform had strong brand awareness but significantly lower conversion rates compared to the US.
Product teams wanted to invest in improving the international experience, but they had no shared understanding of where the platform was falling short for these travellers, or how it compared to the competitors they were losing to.
Without that baseline, each team was making prioritisation decisions in isolation. The Experiences team had no data on how their product compared to GetYourGuide in these markets. The Hotels team had no equivalent view against Booking.com. The Core UX team, responsible for cross-vertical platform features, had no way to tell which gaps were specific to one vertical and which were structural issues that warranted shared investment.
The research challenge
How easy is it for Southern European travellers to discover, consider, and book an Experience or Hotel on Tripadvisor, compared to the leading competitor in each category?
The research question was broad by design. It meant evaluating Tripadvisor Experiences against GetYourGuide and Tripadvisor Hotels against Booking.com across three markets, covering the full funnel from Discovery through Consideration to Booking.
The complexity was not just methodological. Two separate business verticals needed to be tested simultaneously, each with its own competitor, its own product team, and its own set of priorities. The research had to produce findings that were comparable across markets and verticals while still being specific enough for each team to act on. I ran the study from Singapore, while my stakeholders were 12 to 15 hours behind in the US.
What I did and why
I ran 300 unmoderated usability tests on the UserTesting platform. For each vertical, we recruited 25 participants per platform per market: Tripadvisor and GetYourGuide across France, Italy, and Spain for Experiences, and Tripadvisor and Booking.com across the same three markets for Hotels. All tests were conducted on mobile web, which reflected how Southern European travellers predominantly accessed these platforms.
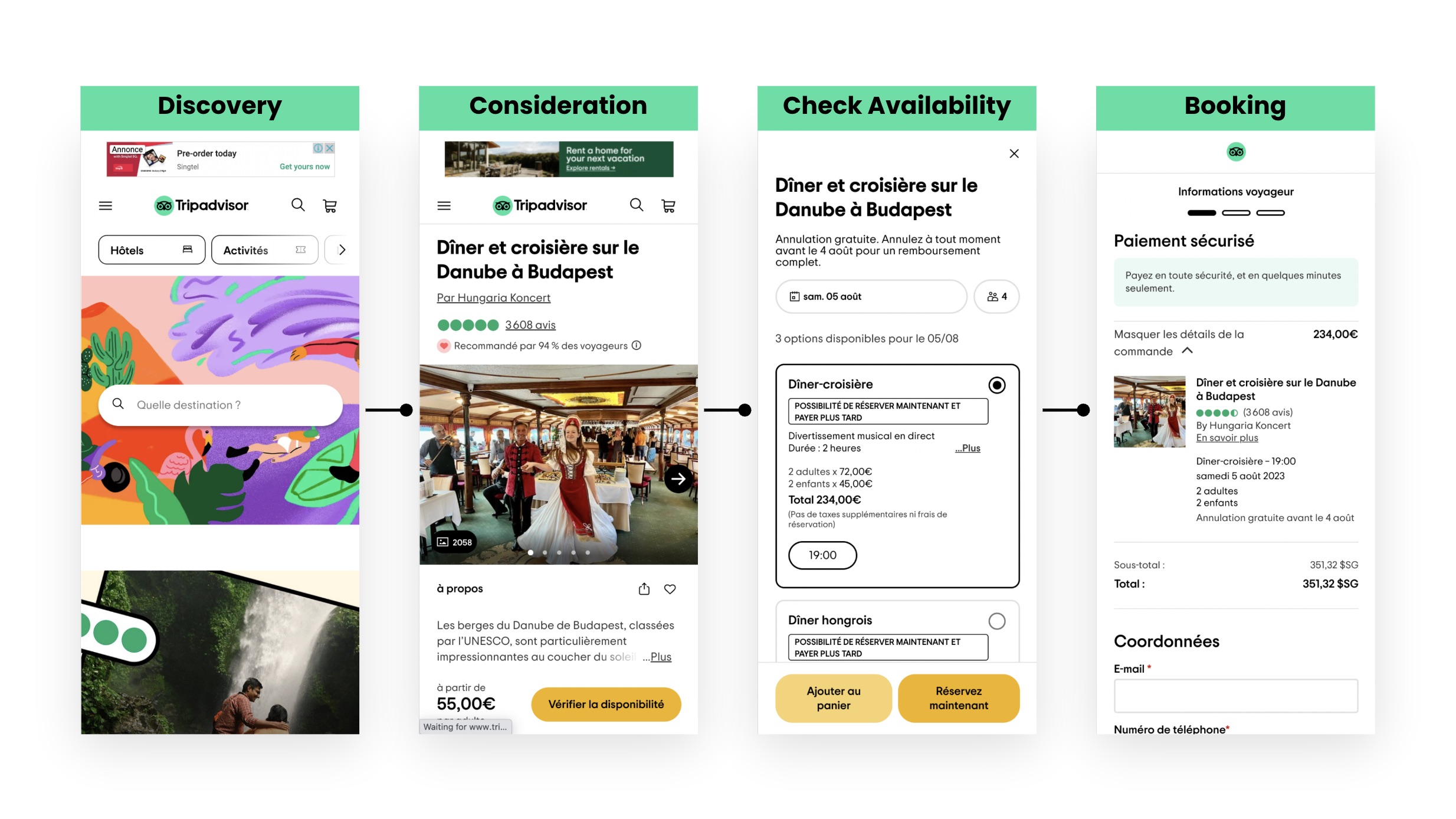
The goal was to establish a usable baseline across markets, not to explore individual behaviours in depth. Unmoderated tests gave me scale and consistency. Every participant followed the same task structure, covering Discovery, Consideration, Check Availability (for Experiences), and Booking. That consistency made the cross-market and cross-platform comparisons valid. It also meant participants completed tasks naturally, without a moderator's presence shaping their behaviour.
Before launching the Southern European tests, I ran a US pilot to stress-test the discussion guide. This mattered because all European tests would be conducted in participants' native languages. The pilot helped me catch flow issues and refine lines of questioning before the Localisation team translated the test instructions into French, Italian, and Spanish. Getting this right in English first meant the translated versions could be accurate rather than approximate.

Each test also included SUPR-Q, a standardised satisfaction metric. It meant I could compare satisfaction consistently across every platform and market combination.
I analysed all 300 tests independently. Participant responses came back in French, Italian, and Spanish, so I used ChatGPT, with appropriate anonymisation, to translate them into English to speed up the analysis. Going through the Localisation team's formal translation process would have added several weeks, and product teams were approaching their milestone planning phase.
I then structured the share-outs sequentially. The Experiences team received their findings first, followed by Hotels, while the Core UX team received a combined report that surfaced cross-vertical patterns. Each team received findings framed for their priorities and their product context, rather than a single report that tried to serve everyone at once.
What we found
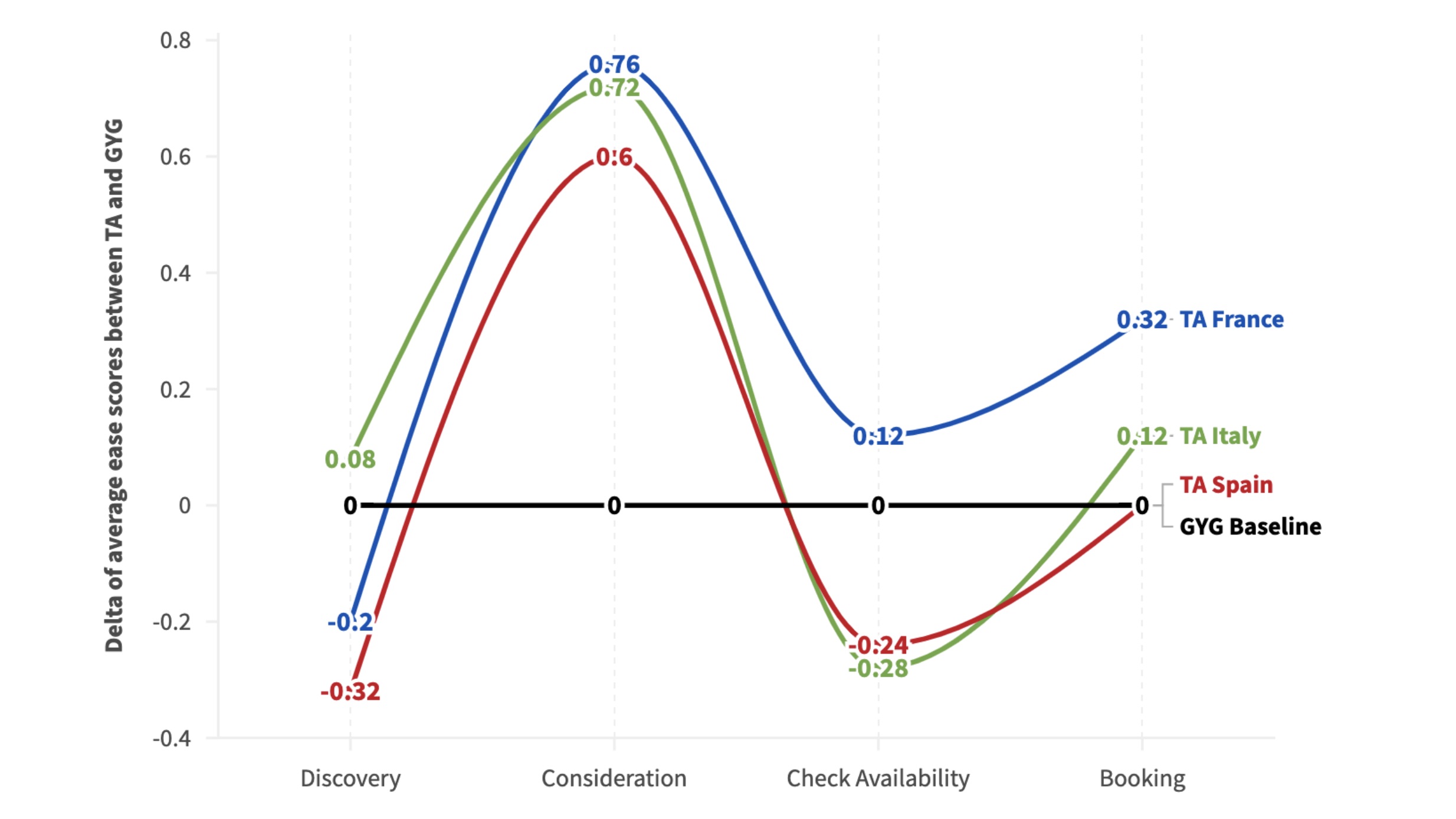
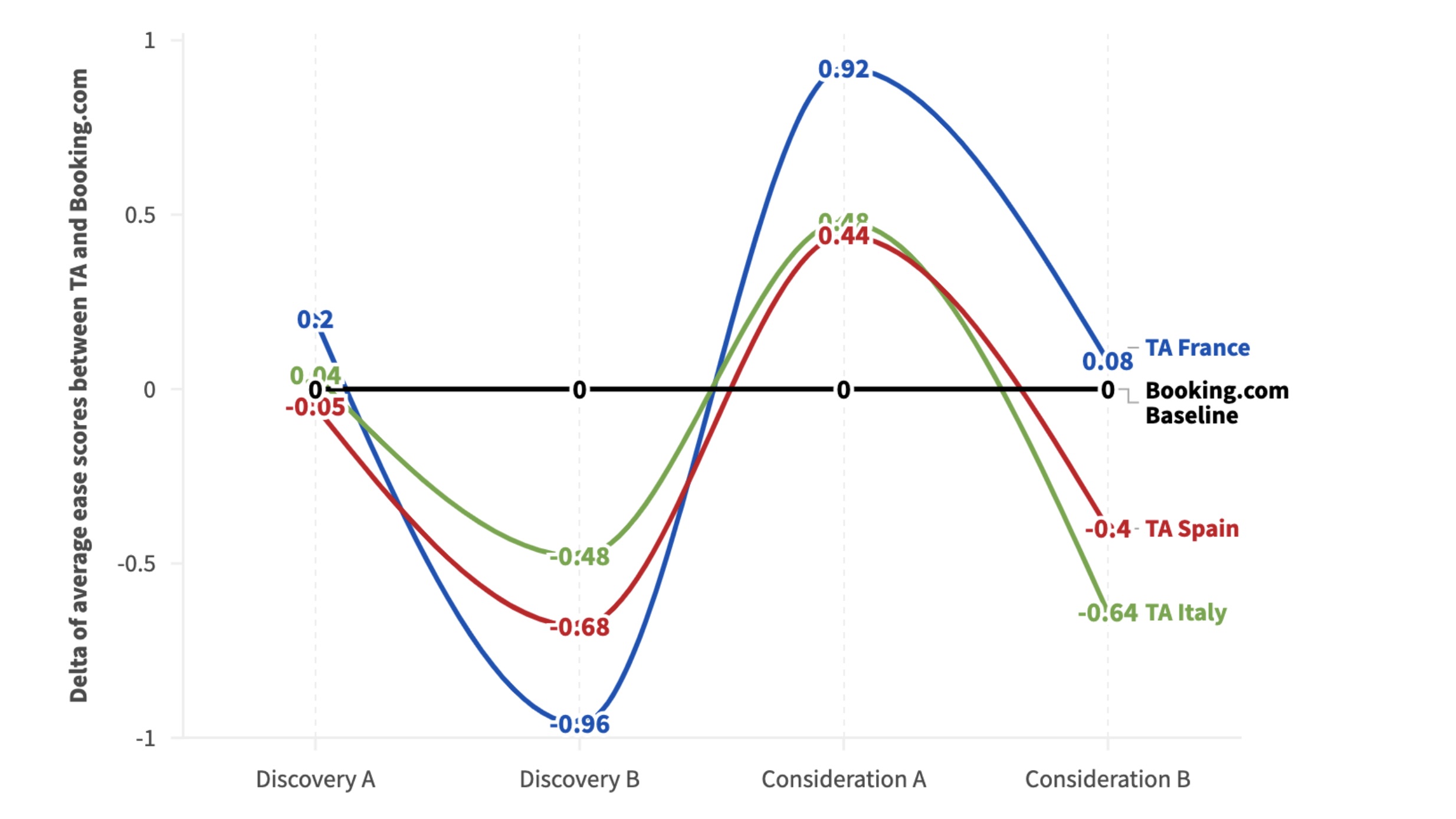
Ease of use scores (Experiences)
Discovery was where the platform consistently fell short across both verticals and most markets. For Experiences, Tripadvisor trailed GetYourGuide at Discovery in France and Spain. For Hotels, Tripadvisor trailed Booking.com considerably at Discovery across Italy and Spain, where ease-of-use scores dropped sharply.
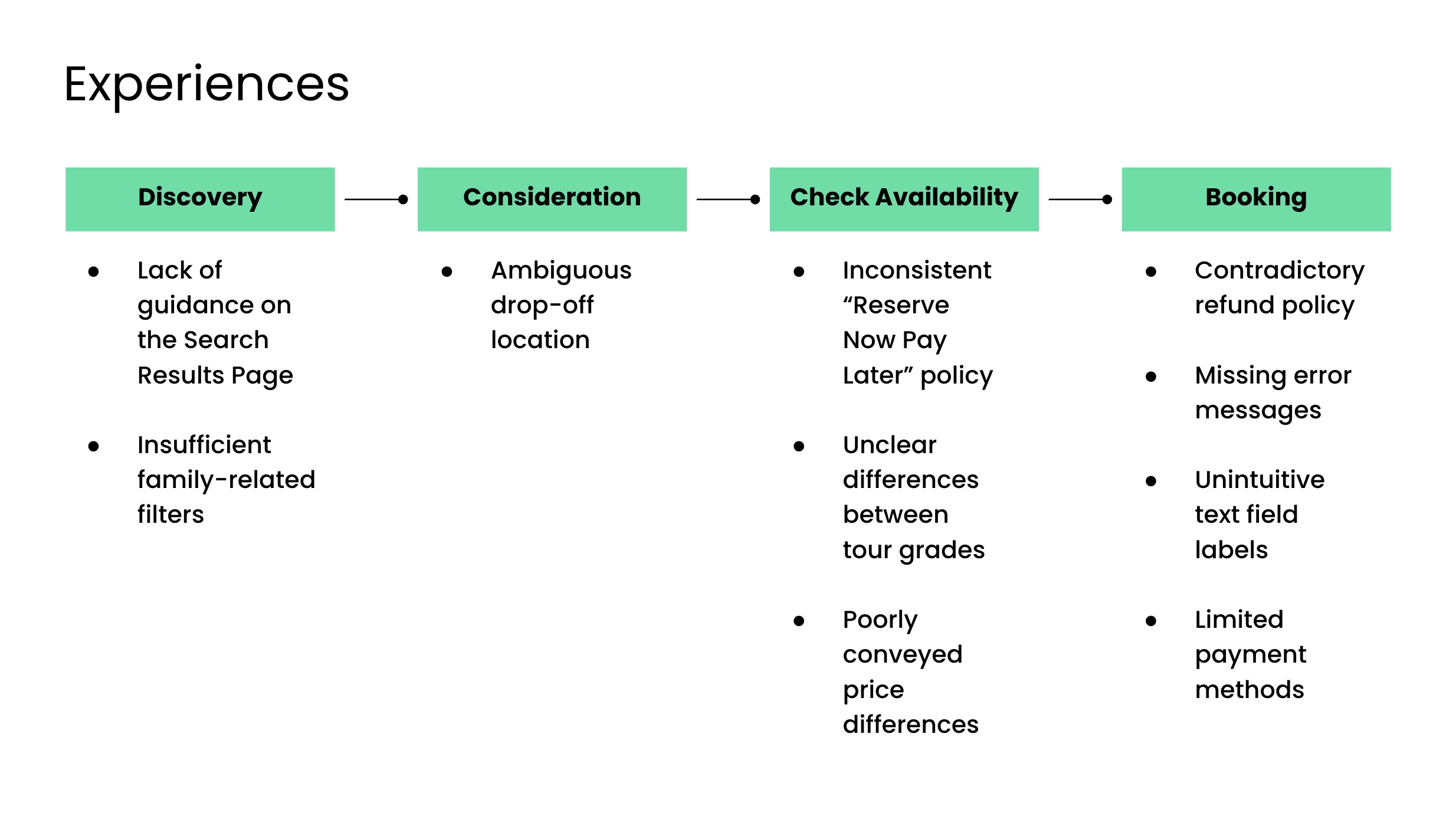
Overview of usability issues (Experiences)
Participants struggled to get from a search query to a useful set of results. The SUPR-Q usability component reflected this pattern. In fact, Tripadvisor scored below GetYourGuide on usability in all three Experiences markets, and below Booking.com on usability in Italy and Spain for Hotels.
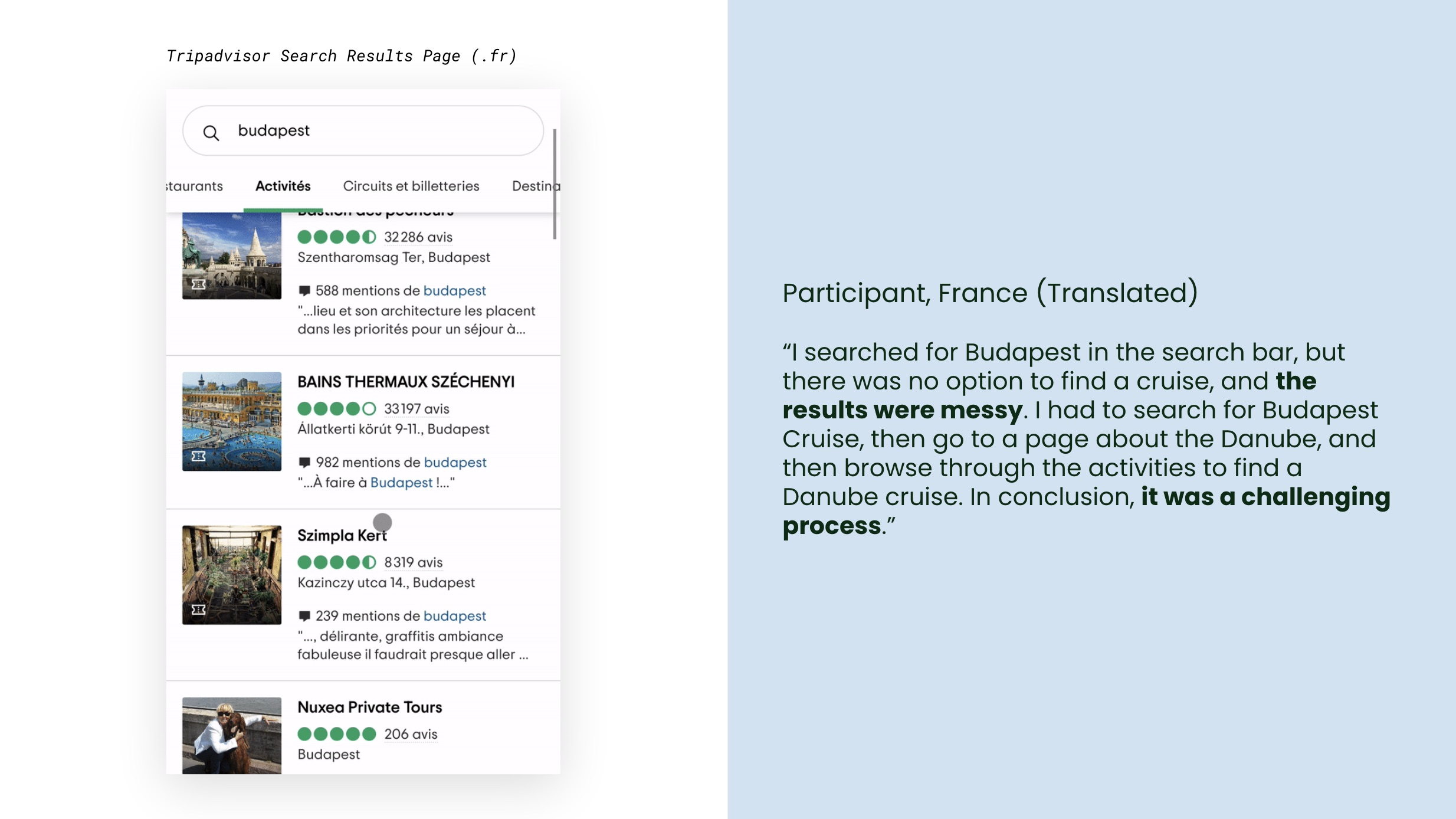
The root cause was consistent: filtering and sorting gaps. For Experiences, Tripadvisor's search results page offered no way to filter by price or duration, two details that Southern European travellers especially looked out for when evaluating experiences.
Over 80% of participants used the search bar on Tripadvisor's homepage, but a third of them ended up on a search results page rather than a dedicated listing page. From there, they had no tools to narrow down what they were seeing. GetYourGuide, by contrast, directed searches to list pages with immediate filtering and sorting options.
The gap was especially sharp for family travellers. Family travel accounts for a higher proportion of domestic and regional trips among Southern European travellers compared to US travellers.
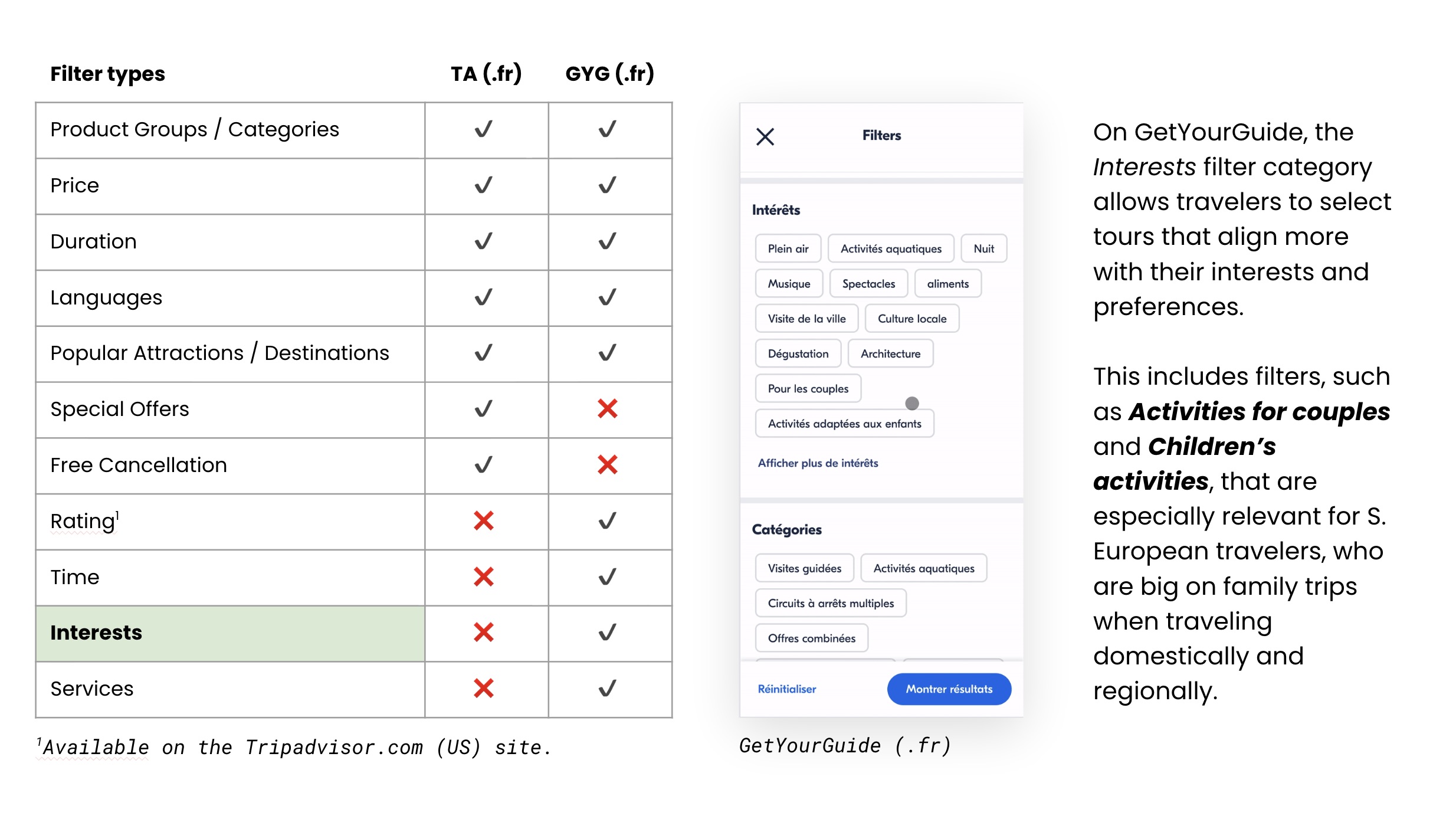
Many French and Spanish participants who landed on a Tripadvisor list page could not find a suitable family experience because there were no family-related filters. They ended up clicking into individual tours one by one to assess their suitability. GetYourGuide offered interest-based filters including "Activities for couples" and "Children's activities" that Tripadvisor did not have.
Price added another layer of friction for Experiences. Southern European travellers are more budget-conscious than their US counterparts, and Tripadvisor's price display made that harder to navigate.
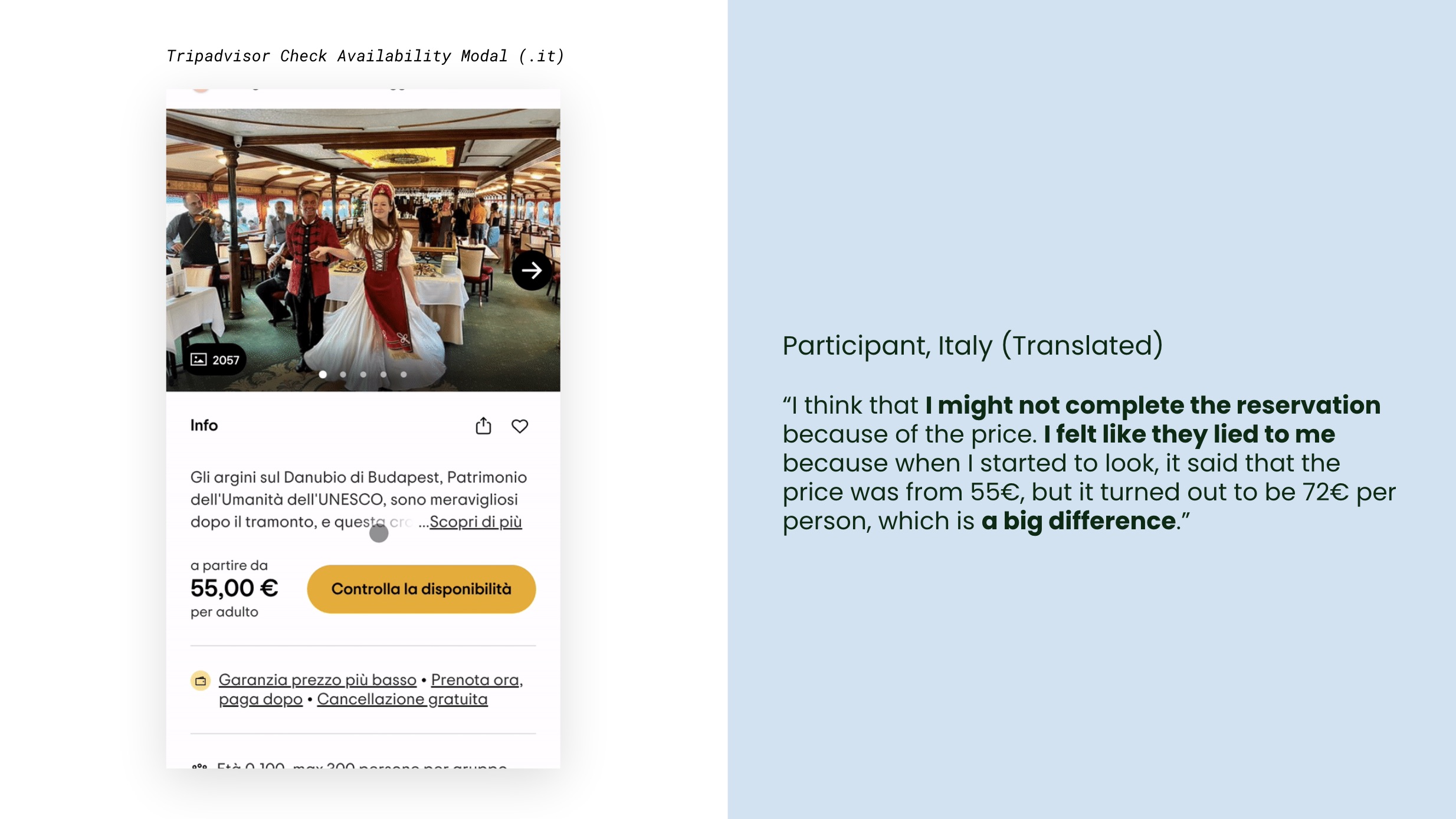
The price shown at the top of a tour detail page, the price in the sticky footer, and the prices listed in the Check Availability modal did not always match. Some participants assumed the discrepancy meant they were being misled, and said it might have caused them to abandon the booking.
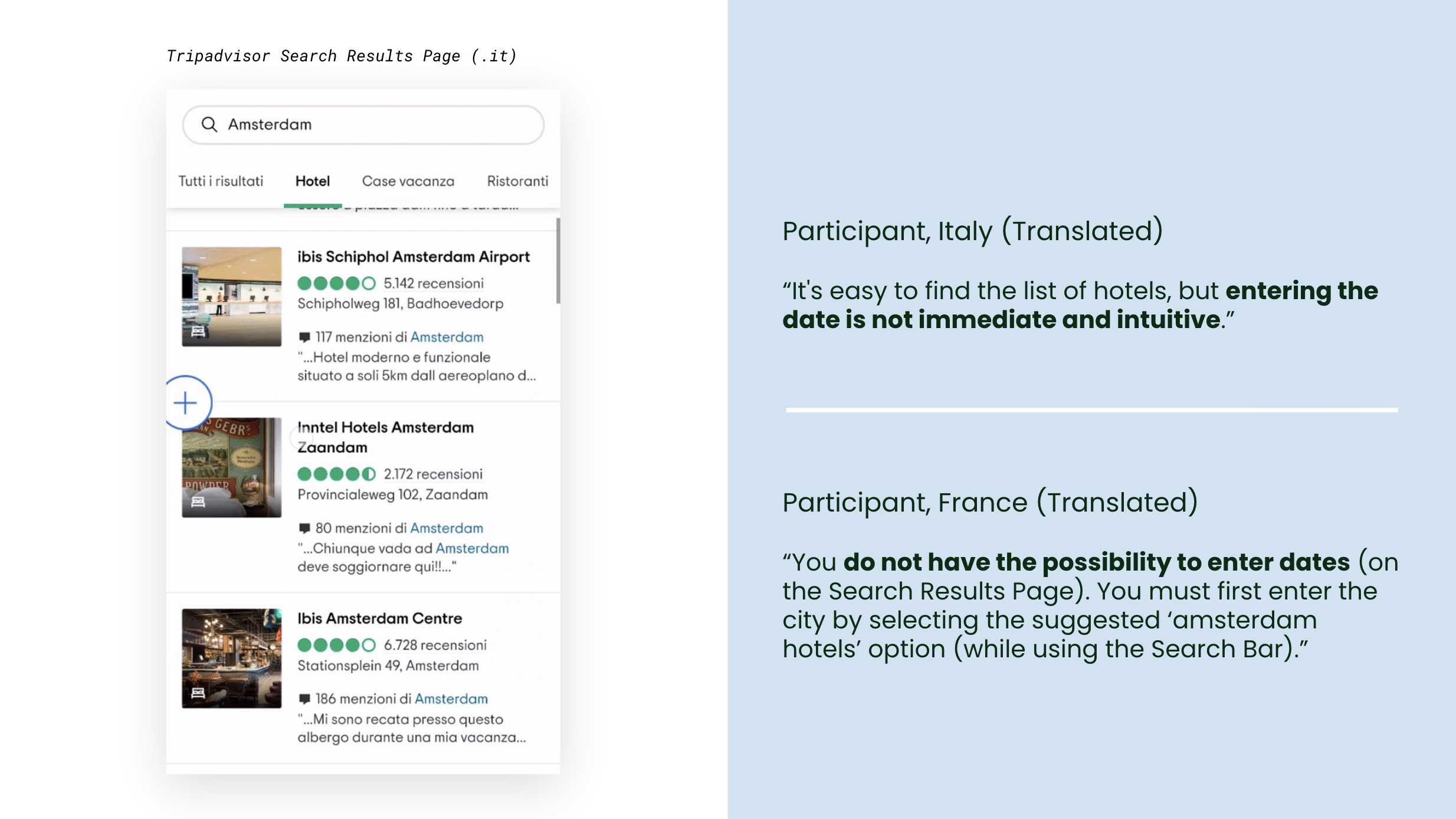
For Hotels, the search experience did not match what participants expected. When participants searched for hotels in Amsterdam, they expected to land on a list page where they could enter dates, specify the number of travellers, and filter results.
Instead, they landed on a search results page with no date entry and no ability to filter or sort. Booking.com's homepage already allowed travellers to specify dates and number of guests before searching. It then directed them straight to a filterable list page.
These were not market-specific quirks. The US pilot had signalled similar issues, and the Southern European data confirmed they were structural. Most usability problems were global, but some hit Southern European travellers harder because their localised sites were missing features that existed on the US version.
What changed
The Experiences team prioritised three features for their milestone roadmap based directly on the research findings:
Price filter optimisation in search
Improve visibility and display a median price dynamic to currency and geography.
Price clarity across the booking flow
Ensure that price is displayed consistently from the tour listing through to the Check Availability modal.
"Good for" contextual filters
Add filters such as Good for families, Local favourites, and Deals to listing and product list pages.
Each traced back to a specific gap the benchmarking had surfaced.
The Hotels team used the findings to address search experience issues, particularly around aligning the search flow with traveller expectations for date entry and filtering capabilities on the localised sites.
The Core UX team received a combined report that surfaced patterns spanning both verticals. This gave them a cross-vertical view they had not had before.
The research also generated enough organisational momentum to spark a follow-on initiative: a Localised Discovery Research programme designed to go deeper into the discovery patterns, search experience, and conversion challenges the benchmarking had surfaced. That programme was later deprioritised due to organisational restructuring, but the decision to pursue it said something about how far the benchmarking had shifted the organisation's thinking.
The benchmarking had also produced a reusable framework. The study structure, task design, and SUPR-Q benchmarking approach were built to be repeated. The intention was to apply the same framework to other priority market regions and to run it periodically, every one to two quarters, to track whether shipped fixes were closing the gaps the research had identified.
The outcome
Three product teams that had previously been making international prioritisation decisions without a shared foundation now had one. The benchmarking established a common baseline across Experiences, Hotels, and Core UX, with specific usability gaps mapped to specific funnel stages, markets, and competitors.
Roadmap decisions were directly traceable to the research rather than based on assumption. The price filter optimisation in search, price clarity improvements across the booking flow, and the "Good for" contextual filters made it to production.
Reflection
Running 300 tests across two verticals and three markets on your own teaches you something about where to standardise and where to stay flexible. The unmoderated format and the SUPR-Q backbone gave me comparability. Every test followed the same structure, and every participant rated the same dimensions. The data could be cut by market, platform, or funnel stage without losing coherence. That standardisation is what made the findings usable for three different teams with three different sets of priorities.
That said, standardisation has a cost. Unmoderated testing tells you what happened and, to a degree, why. It does not give you the follow-up question in the moment, the chance to probe when a participant hesitates or says something unexpected. For a baseline study, that trade-off was right. For the deeper questions the benchmarking surfaced, like why Southern European travellers' discovery patterns differ from US travellers, moderated research would have been the natural next step.
Using AI to translate participant responses was a pragmatic call driven by a real deadline. It worked, but at the cost of nuance that a formal translation process would have preserved. What AI gave me was speed at a moment when it determined whether the findings reached product teams before or after their roadmaps were set. Knowing which trade-off to make, and being honest about what you gave up, is part of running research at scale.